Reason 14 opinia – czy warto? Nowy workflow, RV-9 i realne porównanie DAW
9 kwietnia 2026
Reason 14 – czy to w końcu używalna DAW? Analiza zmian, które naprawdę mają znaczenie
reason 14 opinia w tej wersji nie polega na opisie funkcji. Kluczowe pytanie jest inne: czy Reason w końcu przestaje być niewygodny w pracy.
Przez lata problem nie dotyczył brzmienia ani możliwości. Problemem był workflow. Zbyt wolny, zbyt rozproszony, zbyt zależny od racka.
Reason 14 próbuje to naprawić. Nie kosmetycznie — strukturalnie.
Problem, który Reason ignorował przez lata
Większość DAW już dawno przeszła na model track-based. Czyli wszystko, co ważne, jest przypisane do ścieżki.
Reason działał odwrotnie:
— rack jako centrum — ciągłe przełączanie widoków — chaos przy większych projektach
To nie był problem początkujących. To był problem wydajności.
reason 14 opinia zaczyna się od tego: czy ten problem został rozwiązany?
Nowy workflow: mniej kliknięć, więcej kontroli
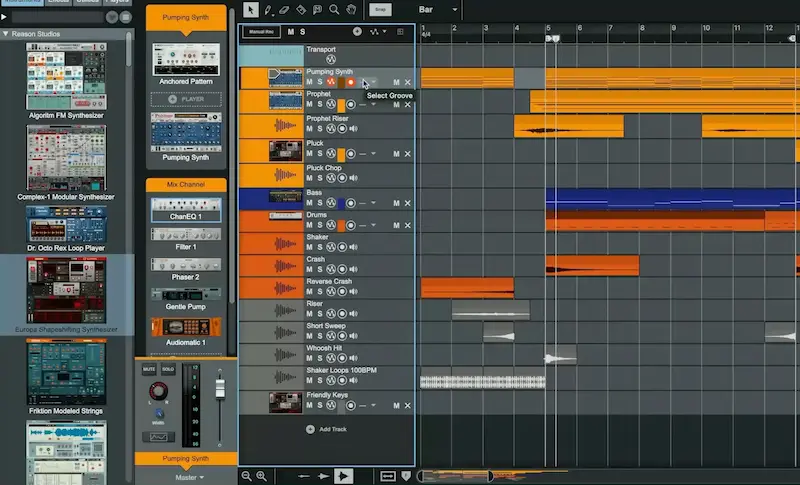
Najważniejsza zmiana to Track Panel.
W jednym miejscu masz:
— efekty — routing — sendy — panoramę
Bez skakania między rackiem a mikserem.
Dodatkowo:
Rack per Track — każdy track ma własny rack.
To wygląda banalnie. Ale w praktyce usuwa jeden z największych problemów Reason — brak kontroli nad sygnałem.
reason 14 opinia w tym miejscu: to pierwsza realna poprawa workflow w historii tego DAW.
Sekwencer: nie nowy, tylko w końcu normalny
Zmiany w sekwencerze nie są rewolucją. Są normalizacją.
Dodano:
— foldery tracków — loop clips — szybsze MIDI — velocity bezpośrednio w klipie
To wszystko istnieje w konkurencji od lat.
Różnica jest taka, że teraz Reason nie spowalnia pracy.
I to jest klucz.
RV-9 Reverb: wygoda zamiast jakości
Nowy reverb to hybryda:
— algorithmic — convolution
Dodatki:
— shimmer — ducking — EQ
Brzmi dobrze na papierze.
W praktyce — to narzędzie do szybkiej pracy, nie do finalnego brzmienia.
Jeśli robisz demo — wystarczy.
Jeśli robisz release — nie.
reason 14 opinia: RV-9 to utility, nie standard jakości.
Gdzie Reason 14 ma sens w realnej pracy
1. Sound design Modularność nadal robi robotę. Tu Reason jest mocny.
2. Szkice i aranżacje Nowy workflow przyspiesza start projektu.
3. Zamknięty system Nie potrzebujesz pluginów na start.
Ale jest granica.
Finalny etap produkcji wymaga precyzji — szczególnie w balansie i dynamice. Dlatego projekty często wychodzą poza DAW i trafiają do zewnętrznej obróbki, np. poprzez profesjonalny mastering online, gdzie materiał jest doprowadzany do standardów dystrybucyjnych.
Gdzie Reason nadal przegrywa
To jest kluczowy blok.
— nie jest najszybszy — nie ma najlepszych narzędzi MIDI — nie jest standardem w branży — ma mniejszy ekosystem
Największy problem:
Reason nie jest pierwszym wyborem w żadnej kategorii.
reason 14 opinia: to DAW bez dominacji.
Porównanie: brutalnie i bez marketingu
Ableton — szybszy FL Studio — lepszy do beatów Logic — lepszy do miksu Cubase — lepszy do MIDI
Reason?
Średni we wszystkim.
Ale teraz — przynajmniej używalny.
Czy warto przejść na Reason 14
Jeśli już używasz Reason — tak.
Jeśli jesteś w innej DAW — nie masz powodu.
To nie jest upgrade, który zmienia rynek.
To upgrade, który naprawia błędy sprzed lat.
reason 14 opinia końcowa:
To pierwszy Reason, który nie przeszkadza w pracy.
Pyramix 16 – analiza DAW do masteringu i Dolby Atmos
9 kwietnia 2026
Pyramix 16 – specjalistyczna DAW do masteringu i Dolby Atmos: analiza techniczna bez uproszczeń
Pyramix 16 nie jest kolejną aktualizacją „dla wszystkich”. To system zaprojektowany pod konkretne scenariusze: nagrania akustyczne, mastering wysokiej rozdzielczości i produkcję immersyjną. W przeciwieństwie do popularnych DAW, które optymalizują workflow i szybkość pracy, Pyramix 16 koncentruje się na fizycznej poprawności sygnału.
To zasadnicza różnica. Jeśli nie pracujesz z realnym materiałem akustycznym, większość jego przewag nie będzie miała znaczenia.
Nowa wersja – zmiana podejścia, nie tylko funkcji
Analizując Pyramix 16, trzeba odrzucić typowe myślenie o update’ach. To nie lista nowych opcji. To zmiana logiki działania systemu.
Trzy kluczowe obszary:
— pełna integracja PanNoir w mikserze — wbudowany Dolby Atmos Renderer — obsługa macOS przez środowisko wirtualne
Każdy z tych elementów wpływa bezpośrednio na sposób pracy z sygnałem.
PanNoir – korekta podstawowego błędu w panoramie
Standardowe DAW traktują panoramę jako balans poziomów między kanałami. To uproszczenie, które ignoruje fizykę propagacji dźwięku.
Pyramix 16 wykorzystuje PanNoir, który dodaje komponent czasowy (time-of-arrival) do klasycznego modelu.
Efekt:
— spójność fazowa między mikrofonami głównymi i dodatkowymi — ograniczenie comb filtering — stabilny obraz stereo — zachowanie głębi sceny
W nagraniach orkiestralnych to nie jest opcja — to warunek poprawnego miksu.
W muzyce elektronicznej różnica będzie znacznie mniej odczuwalna.
Dolby Atmos – integracja zamiast zewnętrznych narzędzi
Pyramix 16 oferuje natywny Dolby Atmos Renderer z obsługą do 9.1.6 oraz monitoringiem binauralnym.
Praktyczne konsekwencje:
— brak konieczności używania dodatkowych aplikacji — uproszczony routing — kontrola loudness w czasie rzeczywistym — spójny pipeline produkcyjny
To nie jest przewaga technologiczna. To konieczność w aktualnym rynku audio.
Porównanie z konkurencją
Żeby właściwie ocenić Pyramix 16, trzeba zestawić go z realnymi alternatywami.
Pro Tools — standard branżowy. Wygrywa integracją i popularnością. Przegrywa w precyzji pracy z sygnałem.
Sequoia — bardzo silna pozycja w masteringu. Stabilność i dokładność, ale bez zaawansowanego modelu przestrzennego.
Nuendo — dominacja w postprodukcji audio do obrazu. Lepsze narzędzia do wideo, słabsza specjalizacja w akustyce.
Pyramix 16 funkcjonuje poza głównym nurtem. To system dla określonego typu pracy.
Realne zastosowania
Najbardziej oczywisty przypadek: nagrania orkiestralne.
Duża liczba mikrofonów powoduje problemy fazowe w klasycznych DAW. Pyramix 16 redukuje te problemy na poziomie systemowym.
Drugi scenariusz: mastering muzyki akustycznej.
Tutaj najmniejsze błędy wpływają na percepcję przestrzeni i balansu.
Trzeci: produkcja immersyjna.
Wbudowany Atmos eliminuje dodatkowe etapy pracy.
W produkcji komercyjnej podejście jest inne. Liczy się szybkość i kompatybilność. W takich przypadkach bardziej efektywne jest łączenie narzędzi oraz korzystanie z usług takich jak profesjonalny mastering online, który pozwala uzyskać spójny rezultat niezależnie od środowiska pracy.
Ograniczenia systemu
Największy problem: brak natywnego wsparcia macOS.
Virtualizacja oznacza większą latencję i ryzyko niestabilności.
Kolejna kwestia: zamknięty ekosystem.
Mniej użytkowników oznacza trudniejszą współpracę.
Trzecie ograniczenie: wąska specjalizacja.
Pyramix 16 nie nadaje się do produkcji kreatywnej ani szybkich projektów.
Mocne strony techniczne
Pyramix 16 wyróżnia się tam, gdzie inne DAW mają ograniczenia:
— przetwarzanie audio w wysokiej rozdzielczości bez degradacji — precyzyjne zarządzanie latencją — zaawansowana obsługa systemów wielokanałowych — natywne wsparcie DSD i DXD — integracja pomiarów loudness
To elementy, które bezpośrednio wpływają na końcowy dźwięk.
Wnioski
Pyramix 16 nie jest narzędziem uniwersalnym.
To system zaprojektowany do konkretnych zastosowań, gdzie liczy się dokładność, a nie wygoda.
Jeśli używasz go zgodnie z przeznaczeniem — działa na najwyższym poziomie. Jeśli nie — staje się zbędnie skomplikowany.
Analiza najpopularniejszych wykonawców w Polsce i na świecie
W 2025 roku streaming muzyki pozostaje jednym z kluczowych źródeł dochodu dla artystów. Platformy takie jak Spotify, Apple Music, YouTube, Amazon Music czy Deezer w coraz większym stopniu decydują o tym, jak muzyka jest konsumowana i monetyzowana. Według danych branżowych Spotify wypłaciło ponad 9 miliardów dolarów właścicielom praw autorskich w 2023 roku, co potwierdza dominującą pozycję tej platformy na globalnym rynku audio.
Rzeczywiste zarobki wykonawców zależą jednak bezpośrednio od liczby odtworzeń. Średnia stawka Spotify wynosi około 0,003–0,0035 USD za stream, natomiast YouTube generuje 0,003–0,005 USD za wyświetlenie, w zależności od rynku reklamowego i kraju. W Polsce przychód za jedno odtworzenie bywa nieco wyższy od średniej światowej, głównie dzięki rosnącej liczbie subskrybentów premium.
Poniżej przedstawiamy analizę najważniejszych artystów z Polski, Ukrainy oraz sceny światowej, ich przybliżone wyniki streamingowe oraz szacunkowe dochody w ujęciu rocznym i pięcioletnim. Wszystkie kwoty mają charakter orientacyjny i nie uwzględniają podziałów z wytwórniami ani podatków.
Najlepiej zarabiający artyści w Polsce (streaming)
Sanah jest obecnie jedną z najczęściej słuchanych artystek w Polsce. Jej utwory regularnie osiągają dziesiątki i setki milionów odtworzeń na Spotify oraz YouTube. Dzięki temu jej roczne przychody ze streamingu sięgają kilku milionów złotych, a stabilna obecność na playlistach zapewnia długoterminowe wpływy.
Dawid Podsiadło od lat pozostaje liderem polskiego rynku muzycznego. Jego katalog generuje setki milionów streamów, co przekłada się na wysokie sześciocyfrowe lub nawet siedmiocyfrowe dochody roczne z platform cyfrowych.
Taco Hemingway to jeden z najbardziej wpływowych artystów hip-hopowych w Polsce. Jego albumy notują ogromne liczby odtworzeń, a streaming zapewnia mu milionowe przychody w skali roku, szczególnie w okresach premierowych.
Quebonafide osiągnął status artysty mainstreamowego bez rezygnacji z hip-hopowych korzeni. Jego katalog cyfrowy generuje setki tysięcy do kilku milionów złotych rocznie.
Bedoes 2115 reprezentuje młodsze pokolenie polskiej sceny. Intensywna obecność w streamingu i lojalna baza fanów pozwalają mu osiągać wysokie przychody cyfrowe już na wczesnym etapie kariery.
Najpopularniejsi artyści z Ukrainy w streamingu
Jerry Heil przeszła drogę od YouTube do międzynarodowych list przebojów w ciągu kilku lat. Do 2025 roku jej katalog zgromadził około 174 milionów streamów na Spotify, co oznacza około 550 tysięcy dolarów przychodu, nie licząc YouTube.
alyona alyona zyskała rozpoznawalność dzięki viralowym hitom. Jej 138 milionów odtworzeń na Spotify przekłada się na około 440 tysięcy dolarów łącznych wpływów.
Max Barskih to jeden z najbardziej eksportowych artystów Ukrainy. Jego dochody ze streamingu na przestrzeni kilku lat szacuje się na 0,5–1 mln dolarów.
MONATIK od dekady utrzymuje wysoką popularność. Jego streamingowe przychody w perspektywie pięciu lat przekraczają 500 tysięcy dolarów.
Go_A zdobył międzynarodową uwagę po Eurowizji. Streaming i YouTube zapewniają zespołowi dziesiątki tysięcy dolarów rocznie.
Największe gwiazdy światowego streamingu
Taylor Swift pozostaje globalnym liderem. W 2023 roku uzyskała 29,1 miliarda streamów na Spotify, co przełożyło się na około 93 miliony dolarów z tej platformy w jednym roku oraz ponad 500 milionów dolarów w pięcioletniej perspektywie.
Bad Bunny dominuje na rynku latynoskim, osiągając 80–100 milionów dolarów rocznie ze streamingu.
Drake, The Weeknd, Ariana Grande, Ed Sheeran, BTS, Justin Bieber, Coldplay oraz Queen generują miliony lub dziesiątki milionów dolarów rocznie, głównie dzięki globalnemu zasięgowi i długowiecznym katalogom.
Streaming stanowi tylko część przychodów. Najlepiej zarabiający muzycy łączą wpływy z platform cyfrowych z koncertami, sprzedażą merchu, współpracami reklamowymi, licencjami do filmów i reklam oraz bezpośrednim wsparciem fanów. W Polsce szczególnie istotne pozostają trasy koncertowe, które często przewyższają dochody ze streamingu.
Profesjonalny mixing i mastering a sukces w streamingu
Jakość brzmienia ma bezpośredni wpływ na widoczność utworów w algorytmach Spotify i YouTube. Profesjonalnie zmiksowane i zmasterowane nagrania osiągają lepsze wyniki odsłuchowe, dłuższy czas słuchania i wyższe przychody.
AREFYEV Studio to internetowe studio specjalizujące się w profesjonalnym mixingu i masteringu. Pomagamy artystom i producentom przygotować utwory zgodnie ze standardami Spotify, Apple Music i YouTube, zapewniając konkurencyjne, nowoczesne brzmienie.
Podsumowanie
Analiza pokazuje, że streaming jest kluczowym, ale nie jedynym źródłem dochodu artystów. Największe sukcesy finansowe osiągają ci, którzy łączą streaming, koncerty, merchandising oraz wysoką jakość produkcji dźwięku. Profesjonalny mixing i mastering pozostają jedną z najbardziej opłacalnych inwestycji w długoterminowy sukces muzyczny.
TOP 5 programów muzycznych DAW 2026 – które naprawdę wybierają użytkownicy w Polsce
28 grudnia 2025
Co roku w środowisku muzycznym powraca to samo pytanie: która DAW jest najlepsza? W 2026 roku odpowiedź staje się wyraźniejsza nie dzięki kampaniom marketingowym, lecz dzięki analizie opinii samych użytkowników – producentów, realizatorów dźwięku i muzyków pracujących na co dzień z oprogramowaniem audio.
Ten materiał powstał na podstawie rzeczywistych ankiet i dyskusji prowadzonych na wyspecjalizowanych platformach branżowych. W analizie uwzględniono dane z Production Expert, Songstuff Music Forum, bloga Bobby’ego Owsinskiego, corocznej ankiety DAW prowadzonej przez ufukonen.com oraz zestawienia publikowane przez Synthtopię. Łącznie w głosowaniach wzięło udział około 29 500 użytkowników z różnych krajów, co pozwala uzyskać wiarygodny obraz faktycznych wyborów w 2026 roku.
Choć nie jest to absolutny przekrój całego rynku, skala próby wystarcza, aby zrozumieć, które programy DAW są realnie używane, a które funkcjonują głównie w niszowych środowiskach.
Jak powstał ten ranking
Warto jasno zaznaczyć kilka kluczowych kwestii. Ten ranking nie jest subiektywną opinią jednego autora. Nie jest też sponsorowanym zestawieniem ani reklamą konkretnych marek. Pozycje zostały ustalone na podstawie łącznej liczby wzmianek i procentowego udziału głosów w kilku niezależnych źródłach.
Takie podejście eliminuje lokalne „bańki popularności” i pokazuje realny układ sił w branży audio, również z perspektywy europejskich użytkowników, w tym rynku polskiego.
Należy pamiętać, że sama DAW nie gwarantuje profesjonalnego brzmienia. Jeśli finalny miks nie spełnia standardów komercyjnych, oprogramowanie traci znaczenie. W naszym studiu realizujemy profesjonalny miks i mastering materiałów nagranych w każdej DAW – od FL Studio po Pro Tools – przygotowując utwory do dystrybucji cyfrowej, radia i współpracy z wytwórniami.
TOP 5 programów muzycznych DAW 2026
5 miejsce — FL Studio: szybki start i masowa popularność
Zestawienie otwiera FL Studio firmy Image-Line. To jedna z najbardziej rozpoznawalnych stacji roboczych audio na świecie, szczególnie popularna wśród beatmakerów, producentów muzyki elektronicznej i osób rozpoczynających przygodę z produkcją.
FL Studio od lat cenione jest za intuicyjny sposób pracy, który pozwala bardzo szybko przenosić pomysły do projektu. Charakterystyczna logika oparta na patternach sprawdza się zarówno w trapie, hip-hopie, EDM-ie, jak i w popowych aranżacjach.
Wbrew obiegowym opiniom, FL Studio już dawno przestało być narzędziem wyłącznie dla początkujących. W 2026 roku oferuje rozbudowane możliwości nagrywania audio, edycji, miksu oraz wstępnego masteringu. W tureckiej ankiecie DAW program zdobył aż 19% głosów, zajmując drugą pozycję, jednak w ujęciu globalnym uplasował się na piątym miejscu.
4 miejsce — Cubase: fundament nowoczesnej produkcji
Cubase od Steinberga to jedna z najstarszych i najbardziej wpływowych DAW w historii. Program zadebiutował w 1989 roku i w dużej mierze ukształtował standardy, które do dziś obowiązują w cyfrowych stacjach roboczych audio.
Cubase od lat kojarzony jest z zaawansowaną edycją MIDI, tworzeniem aranżacji oraz pracą nad muzyką filmową i orkiestrową. Na rynku polskim cieszy się szczególnym uznaniem wśród kompozytorów, producentów muzyki użytkowej i twórców soundtracków.
Mimo wizerunku DAW zorientowanej na MIDI, Cubase pozostaje rozwiązaniem uniwersalnym. W 2026 roku jest powszechnie wykorzystywany do nagrań wokali, instrumentów akustycznych, miksu i pełnej produkcji albumów w różnych gatunkach.
3 miejsce — Studio One: nowoczesna równowaga
Na trzeciej pozycji znalazła się Studio One firmy PreSonus. To stosunkowo młoda DAW, która zadebiutowała w 2009 roku, stworzona przez zespół inżynierów wcześniej pracujących przy rozwoju Cubase.
Studio One zdobyła popularność dzięki przejrzystemu interfejsowi i bardzo płynnemu workflow. Program nie faworyzuje jednego etapu produkcji – równie dobrze sprawdza się podczas nagrań, aranżacji, miksu i przygotowania finalnych wersji utworów.
W 2026 roku Studio One konsekwentnie utrzymuje wysokie pozycje w zestawieniach branżowych: trzecie miejsce w Production Expert, trzecie w tureckiej ankiecie DAW oraz stabilne miejsca w rankingach Bobby’ego Owsinskiego. To przykład DAW, która nie próbuje dominować w jednej kategorii, ale oferuje solidność na każdym etapie pracy.
2 miejsce — Logic Pro: kompletne środowisko dla twórców
Drugie miejsce zajmuje Logic Pro, który od lat pozostaje jednym z najczęściej wybieranych programów przez niezależnych artystów i producentów. Po przejęciu przez Apple stał się narzędziem dostępnym wyłącznie na macOS, co nie przeszkodziło mu zbudować ogromnej społeczności użytkowników.
Logic Pro regularnie zajmuje czołowe miejsca w ankietach – pierwsze na Songstuff Music Forum, pierwsze w tureckim badaniu DAW oraz drugie miejsce w Production Expert 2026.
Jednym z największych atutów Logic Pro jest rozbudowana biblioteka instrumentów wirtualnych, efektów i sampli. Dla wielu twórców w Polsce jest to rozwiązanie „wszystko w jednym”, które pozwala produkować kompletne utwory bez konieczności inwestowania w zewnętrzne wtyczki.
1 miejsce — Pro Tools: branżowy standard
Liderem rankingu 2026 roku pozostaje Pro Tools firmy Avid. Od ponad trzech dekad program ten uznawany jest za standard w profesjonalnej realizacji dźwięku.
Pro Tools zajmuje pierwsze miejsca w zestawieniach Production Expert oraz w badaniach Bobby’ego Owsinskiego i niezmiennie dominuje wśród zawodowych realizatorów dźwięku w latach 2023–2026.
To narzędzie powszechnie wykorzystywane w komercyjnych studiach nagraniowych, telewizji, postprodukcji filmowej oraz przy nagraniach wokali i instrumentów na najwyższym poziomie. Mimo silnej konkurencji, Pro Tools pozostaje kluczowym środowiskiem do miksu i postprodukcji audio.
Dlaczego w rankingu nie ma Samplitude i innych DAW
Często pojawiają się pytania o Samplitude oraz mniej popularne programy. Odpowiedź jest prosta: ich udział w głosowaniach był na tyle niewielki, że nie pozwolił im znaleźć się nawet w rozszerzonym TOP 15.
Praktyka pokazuje, że rynek DAW od lat jest podzielony między kilku głównych graczy, którzy zamieniają się miejscami w zależności od roku i grupy odbiorców. Ostatecznie jednak najważniejsze nie jest to, w jakiej DAW pracujesz, lecz jak brzmi finalny efekt. Dlatego profesjonalny miks i mastering pozostają kluczowym etapem każdego wydania – niezależnie od wybranego oprogramowania.
Acon Digital prezentuje Extract:Dialogue 2 — nowy standard czyszczenia mowy w postprodukcji
23 grudnia 2025
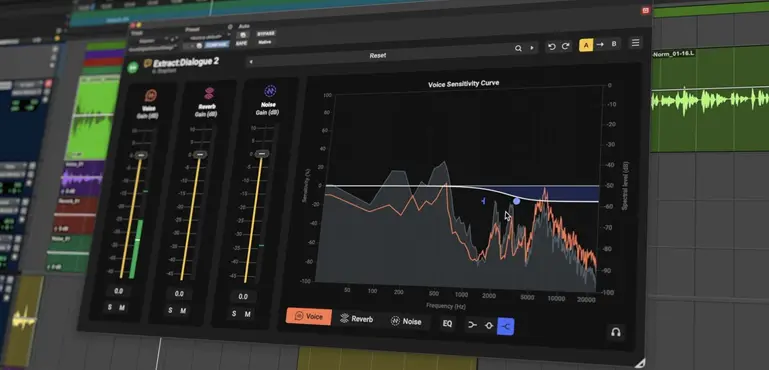
Firma Acon Digital wprowadziła na rynek Extract:Dialogue 2 — odświeżoną wersję swojego zaawansowanego pluginu do obróbki i rekonstrukcji dialogów, przeznaczonego do pracy w filmie, telewizji, projektach streamingowych oraz profesjonalnej postprodukcji audio. Druga odsłona narzędzia oferuje znacznie rozszerzone możliwości oraz całkowicie przeprojektowany interfejs, dzięki czemu proces oczyszczania mowy stał się szybszy i bardziej intuicyjny.
Najważniejszą nowością jest inteligentna redukcja pogłosu działająca w czasie rzeczywistym. Funkcja ta skutecznie ogranicza odbicia pomieszczenia, nie wpływając negatywnie na czytelność ani naturalne brzmienie głosu. Dodatkowo każdy element sygnału audio — dialog, szum oraz ambience — otrzymał własną sekcję korekcji EQ, a kontrola poziomów została przeniesiona do wygodnego interfejsu miksera.
Projektowany z myślą o realnej pracy dźwiękowców
Jak podkreślają przedstawiciele Acon Digital, podczas tworzenia Extract:Dialogue 2 zespół ściśle współpracował z edytorami dialogów, mikserami dubbingu oraz specjalistami ADR. Zebrane doświadczenia pokazały, że największymi wyzwaniami w obróbce mowy są nadmierny pogłos, utrata barwy głosu oraz konieczność używania kilku różnych pluginów jednocześnie.
Nowa wersja Extract:Dialogue eliminuje te problemy w ramach jednego narzędzia, pozwalając zachować charakter oryginalnego nagrania przy jednoczesnym podniesieniu jego jakości technicznej.
Najważniejsze funkcje Extract:Dialogue 2
Ulepszone algorytmy AI zapewniające precyzyjniejsze rozdzielanie sygnału i minimalną liczbę artefaktów
Redukcja pogłosu z regulacją częstotliwości i natychmiastową reakcją
Interfejs typu mikser z tłumikami, przyciskami Solo i Mute oraz wizualną analizą sygnału
Oddzielny korektor EQ dla dialogu, szumu i tła akustycznego
Obsługa przetwarzania Mid-Side dla materiału stereo
Możliwość osobnego wyjścia dialogu, szumu i pogłosu do kompatybilnych DAW
Niska latencja, idealna do interaktywnej pracy w postprodukcji
„Zależało nam na zapewnieniu specjalistom większej kontroli wizualnej i niezależnego zarządzania wszystkimi elementami sygnału. Extract:Dialogue 2 powstał z myślą o realnych sesjach roboczych — od kina fabularnego po dokumentalne wywiady” — powiedział CEO Acon Digital, Stian Oagedal.
Kompatybilność i formaty
Plugin jest dostępny dla systemów Windows 7 i nowszych oraz macOS 10.13 i wyżej. Obsługuje formaty VST, VST3, AU oraz AAX, dzięki czemu może być używany w większości profesjonalnych stacji roboczych audio (DAW).
Cena i aktualizacje
W momencie premiery Extract:Dialogue 2 kosztuje 99 USD. Do 5 stycznia 2026 roku obowiązuje rabat 20%. Użytkownicy poprzedniej wersji Extract:Dialogue oraz posiadacze Acoustica 7 Premium i Acoustica 7 Post Production Suite mogą dokonać aktualizacji za 49 USD poprzez konto użytkownika na stronie Acon Digital. Plugin jest również częścią wszystkich nowych licencji Acoustica 7 Premium oraz Post Production Suite.
Firma PSPaudioware zaprezentowała nową wersję swojego flagowego, modularnego channel stripu — PSP InfiniStrip Earth. Aktualizacja wprowadza aż pięć nowych modułów procesorów, które znacząco poszerzają możliwości obróbki dźwięku i pozwalają jeszcze szybciej oraz precyzyjniej dopasować narzędzie do konkretnych zadań. Nowa wersja została zaprojektowana zarówno z myślą o pracy studyjnej, jak i o realizacji dźwięku na żywo oraz w zastosowaniach broadcastowych.
Wersja PSP InfiniStrip Earth v1.4.0 powstała w oparciu o realne scenariusze użycia: nagrywanie wokali i instrumentów, miks, monitoring na żywo oraz produkcję dla radia i telewizji. Fundamentem wtyczki jest ponad 20 lat doświadczenia PSPaudioware w tworzeniu profesjonalnych procesorów audio.
Nowe moduły w PSP InfiniStrip Earth
Najnowsza aktualizacja dodaje pięć wyspecjalizowanych narzędzi, z których każde odpowiada za inny aspekt kształtowania brzmienia:
Levelizer Inteligentny moduł automatycznego wyrównywania głośności. Utrzymuje stabilny poziom sygnału bez agresywnej kompresji, co doskonale sprawdza się przy wokalach i instrumentach akustycznych.
SnapForger Procesor do precyzyjnej kontroli transjentów oraz wybrzmień. Umożliwia podkreślenie ataku lub wygładzenie sygnału, w zależności od potrzeb miksu.
TiltEQ Korektor z funkcją nachylenia charakterystyki częstotliwościowej i korekcją konturową. Idealny do szybkiej zmiany balansu tonalnego bez skomplikowanej konfiguracji pasm.
Enhancer Dynamiczny wzmacniacz niskich i wysokich częstotliwości. Dodaje klarowności i przestrzeni, zachowując naturalne i muzyczne brzmienie.
BigBass Dedykowany syntezator subbasu, stworzony do wzmocnienia i rozszerzenia dolnego pasma. Świetnie sprawdza się w muzyce elektronicznej, hip-hopie, produkcjach filmowych i nowoczesnym sound designie.
Kluczowe funkcje PSP InfiniStrip Earth
Pełna modularność — ponad 30 modułów, które można dowolnie łączyć i przestawiać
Szybkie dopasowanie do zadania — natychmiastowa zmiana łańcucha pod nagrania, miks lub live
Unikalne procesory — ekskluzywne moduły niedostępne w innych channel stripach
Inteligentne mapowanie parametrów — wymiana modułów bez utraty logiki ustawień
Obsługa zewnętrznego sidechainu we wszystkich procesorach dynamicznych
Zerowa latencja (Zero Latency) — bezpieczna praca podczas nagrywania i monitoringu
Charakterystyczne brzmienie PSP — ciepłe, muzyczne i profesjonalne, cenione w studiach na całym świecie
Dostępne formaty wtyczki: VST / VST3 / AU / AAX. Autoryzacja odbywa się przez system PACE iLok — bez konieczności użycia fizycznego klucza USB (możliwa autoryzacja programowa).
Cena i dostępność
Obecnie PSP InfiniStrip Earth dostępny jest w promocyjnej cenie 99 USD. Oferta obowiązuje do 31 grudnia 2025 roku, po czym cena regularna wzrośnie do 199 USD. Producent udostępnia również 30-dniową wersję demo, pozwalającą w pełni przetestować wtyczkę przed zakupem.
Użytkownicy, którzy kupili PSP InfiniStrip w 2025 roku, otrzymują aktualizację bezpłatnie. Dla wcześniejszych klientów przewidziana jest aktualizacja w obniżonej cenie, dostępna po zalogowaniu na konto użytkownika na stronie PSPaudioware.
Bezpłatną wersję demonstracyjną można pobrać z oficjalnej strony: pspaudioware.
Rzadki „Mix Me DJ” – zabawkowa konsola DJ (ok. 2004) z mini-grooveboxem lo-fi
31 października 2025
Ta niezwykle rzadka zabawkowa konsola DJ – „Mix Me DJ” (lub raczej – mini-groovebox) pojawiła się około 2004 roku i dziś trudno ją spotkać na rynku. Mimo kompaktowych rozmiarów urządzenie zaskakuje liczbą wbudowanych próbek dźwiękowych, efektów oraz lo-fi pętli muzycznych. Obudowa w kolorze srebrnym z sześcioma czerwonymi, migającymi padami perkusyjnymi wygląda bardzo efektownie i przywodzi na myśl prawdziwy pulpit DJ-ski w miniaturze.
W przeciwieństwie do bardziej zaawansowanego modelu „Beat Square – Mix Evolution”, tutaj pokrętło scratch pełni jedynie podstawową funkcję: przy obrocie w dowolnym kierunku aktywuje jedną próbkę, nie reagując na prędkość obrotu. Wszystkie dźwięki to cyfrowe próbki o niskiej lub średniej rozdzielczości, co daje charakterystyczny, lekko „pikselowy” szum i zniekształcenia znane z urządzeń 8-bitowych.
Podobnie jak w modelu Mix Evolution, „Mix Me DJ” wyposażono w niewielką klawiaturę na jedną oktawę, która wysuwa się z obudowy niczym taca CD. Klawisze oferują 10 presetów brzmień instrumentalnych oraz 2 krótkie pętle syntezatorowe. Panel sterowania nutami tła jest stylizowany na kasetowy odtwarzacz — choć w rzeczywistości znajdziemy tylko trzy przyciski: Play, Pause i Stop.
Wzory tła muzycznego są utrzymane w stylach techno oraz hip-hop i zawierają wiele nietypowych barw syntezatorowych. Przyciski zmiany tempa (+/–) regulują prędkość odtwarzania próbek (analogicznie do pitcha w gramofonach winylowych), jednak każdy nowy pattern przywraca tempo do wartości wyjściowej.
Niestety, w tym modelu brak wbudowanego wokodera, który znalazł się w wersji Mix Evolution.
Wady i konstrukcyjne detale
Największą wadą urządzenia jest brak głównego regulatora głośności. W ustawieniach fabrycznych konsola gra bardzo głośno i dosłownie „krzyczy” z wbudowanego głośnika. Chociaż można zmieniać natężenie dźwięku tła i padów za pomocą osobnych przycisków cyfrowych, a dla wejścia AUX/CD przewidziano analogowy regulator, dźwięk klawiatury i scratch-dysku zawsze odtwarzany jest na maksymalnej głośności.
Kolejną niedogodnością są błędy w matrycy klawiatury — przy jednoczesnym naciśnięciu wielu klawiszy polifoniczna gra staje się niepewna i może dochodzić do zakłóceń. Niemniej jednak, dzięki krótkim i jedno-warstwowym próbką można to obejść szybkim przebiegiem akordów zamiast trzymać klawisze.
Na pudełku urządzenia widnieją marki Kid’s Com oraz Happy People, natomiast w USA wydano wersję pod marką Kawasaki, wyróżniającą się kolorem obudowy.
Główne specyfikacje
Klawiatura na 13 klawiszy (panel wysuwany)
6 plastikowych padów perkusyjnych z czerwonymi diodami LED
Wbudowany głośnik mono z lekkim basem
Do 3-głosowej polifonii (w praktyce – mono)
10 presetów brzmień klawiatury (po 2 na każdy z 5 przycisków)
2 dodatkowe pętle syntezatorowe
21 tła muzycznych patternów
Przyciski tempa (+/–) z 16 poziomami regulacji
Sterowanie w stylu kasetowego odtwarzacza (Play / Pause / Stop)
Oddzielna regulacja głośności tła i padów
Analogowy regulator głośności dla wejścia AUX/CD
Scratch-dysk z 21 zestawami efektów (3 przyciski × 7 trybów)
Wewnątrz urządzenia znajdują się ukryte funkcje, aktywowane kombinacjami klawiszy. Przykładowo, można odblokować 7 nowych wzorców rytmicznych lub włączyć regulację głośności klawiatury. Entuzjaści często modyfikują tę konsolę, dodając:
potencjometr głównej głośności;
gniazdo dla zasilacza z regulacją napięcia;
wyjścia audio i przełącznik wyłączenia wbudowanego głośnika;
diody dla korekcji błędów w matrycy klawiatury;
nowe przyciski dla rytmów 22-28 oraz regulację głośności klawiatury;
manualne regulatory pitch oraz trzy potencjometry do precyzyjnego dostrojenia.
Dzięki tym modyfikacjom, konsola staje się zaskakująco ekspresyjnym narzędziem lo-fi dla kreatywnych dźwiękowców-hobbystów.
Ogólne wrażenie
Pod względem wizualnym, konsola wciąż robi wrażenie – srebrna obudowa w połączeniu z czerwonym podświetleniem padów wygląda nowocześnie nawet dziś. Diody na padach migoczą w losowym rytmie, tworząc atmosferę mini-imprezy. Po naciśnięciu jednego pada pozostałe gasną na około siedem sekund, co jest ciekawym efektem wizualnym.
Z drugiej strony, obudowa łatwo ulega zarysowaniom, a głośność wbudowanego głośnika bywa męcząca przy dłuższym użyciu. Brak wyjścia na słuchawki i globalnego regulatora głośności sprawia, że sprzęt nie jest najbardziej komfortowy do dłuższych sesji.
Jednakże dla kolekcjonerów i fanów dźwiękowych zabawek retro, Mix Me DJ to prawdziwy artefakt początku lat 2000-tych — z niepowtarzalnym lo-fi urokiem, charakterystycznymi technologicznymi próbkami i unikalną estetyką taniego syntezatora-zabawki.
iZotope Ozone 12: nowa jakość inteligentnego masteringu
3 września 2025
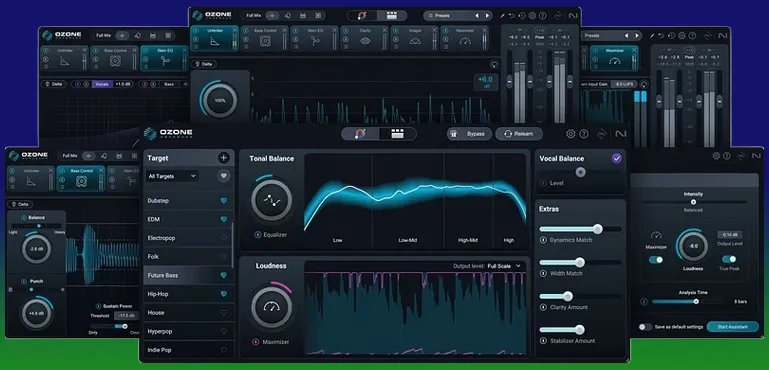
Firma iZotope zaprezentowała Ozone 12 — kluczową aktualizację swojej flagowej kolekcji wtyczek do masteringu. Wersja ta wprowadza trzy całkowicie nowe moduły, bardziej elastyczny Master Assistant oraz odświeżony algorytm limitowania dla modułu Maximizer. Razem rozwiązują typowe wyzwania podczas masteringu — od precyzyjnej korekcji grup instrumentów po przywrócenie dynamiki w przekompresowanych miksach.
Najważniejsze nowości w Ozone 12
Stem EQ
Inteligentny equalizer łączący separację ścieżek (stems) z klasyczną korekcją częstotliwości. Możesz niezależnie korygować wokale, perkusję, bas i inne instrumenty w jednym pliku stereo — bez konieczności powrotu do projektu wielościeżkowego. To ogromna oszczędność czasu i gwarancja, że zmiany będą precyzyjne i bezpieczne dla całego miksu.
Bass Control
Moduł oparty na uczeniu maszynowym, który dopracowuje dolne pasmo — suby i bas. Zapewnia spójne i potężne brzmienie na różnych systemach odsłuchowych, od klubowych głośników aż po słuchawki. Okazuje się przydatny nie tylko w muzyce elektronicznej, lecz także rocku, jazzie czy akustycznych aranżacjach.
Unlimiter
„Anty-limitator”, idealny do ożywienia miksów utraconych przez nadmierne limitowanie lub kompresję. Przywraca transjenty i fragmenty zakresu dynamiki, dodając miksowi przestrzeni i przejrzystości.
Master Assistant i Maximizer: więcej kontroli, mniej artefaktów
W Ozone 12 Master Assistant stał się w pełni konfigurowalny — możesz samodzielnie dobierać moduły, które mają być użyte lub pominięte, ustawiać docelowe poziomy LUFS oraz wybierać ustawienia pod gatunek muzyczny. To znaczy, że masz solidny punkt startowy, ale nadal pełną swobodę twórczą. Maximizer zyskał nowy tryb IRC 5, który podnosi głośność i klarowność bez typowego efektu „pompowania” czy zniekształceń. Idealny do energicznych gatunków, gdzie głośność jest kluczowa.
Edycje i skład pakietów
Ozone 12 dostępny jest w trzech wersjach: Elements, Standard i Advanced. Wersja Advanced zawiera wszystkie moduły oraz ponad 20 wtyczek dostępnych jako osobne komponenty — idealne do elastycznego dopasowania w dowolnym łańcuchu w DAW.
Music Production Suite 8: Ozone 12 i seria Catalyst
Równolegle został zaktualizowany flagowy zestaw Music Production Suite 8, który teraz obejmuje Ozone 12 Advanced oraz wszystkie pięć wtyczek z serii Catalyst — FXEQ, Velvet, Cascadia, Aurora i Plasma. Łącznie ponad 100 wtyczek, w tym Neutron 5, Nectar 4, RX 11 Standard, a także efekty i narzędzia od Native Instruments, Plugin Alliance i Brainworx. Kompletny pakiet do miksowania, masteringu i sound-designu.
Kompatybilność
Systemy operacyjne: Windows 10 (22H2) / Windows 11 (24H2); macOS Ventura 13.7, Sonoma 14.7, Sequoia 15.x
Architektury Mac: Intel i Apple Silicon (serie M), obsługiwane natywnie i przez Rosettę
Formaty wtyczek: AAX, AU, VST3 (tylko 64-bit). VST2 nie jest już wspierane
Cena i dostępność
Ozone 12 Elements — 55 USD
Ozone 12 Standard — 219 USD
Ozone 12 Advanced — 499 USD
Music Production Suite 8 — 799 USD
Obecni użytkownicy iZotope mogą skorzystać ze specjalnych ofert lojalnościowych. Dodatkowo, do 6 października 2025 r. dostępna jest dodatkowa zniżka 25 %.
Za każdym profesjonalnie brzmiącym utworem stoją nie tylko artyści i producenci, ale także dwie kluczowe osoby: inżynier miksu i inżynier masteringu. To właśnie oni odpowiadają za końcowe brzmienie muzyki, nadając jej jakość i charakter, które sprawiają, że utwór wyróżnia się na Spotify, YouTube czy radiu. Choć te funkcje często się mylą, w rzeczywistości różnią się zakresem obowiązków i odpowiedzialnością. W tym artykule dowiesz się, czym się zajmują, gdzie się tego nauczyć, ile zarabiają w Polsce i na świecie oraz jakie możliwości rozwoju daje ten zawód.
Kim jest inżynier miksu?
Inżynier miksu (mixing engineer) to osoba, która łączy wszystkie ścieżki dźwiękowe — wokal, perkusję, bas, instrumenty klawiszowe itp. — w spójną i przyjemną całość. To swoisty projektant dźwięku, który sprawia, że utwór nabiera kształtu przed ostatecznym masteringiem.
Główne zadania:
Ustalanie balansu poziomów wszystkich instrumentów;
Praca z equalizerami, kompresorami i efektami;
Tworzenie głębi i przestrzeni poprzez pogłos i panoramowanie;
Inżynier masteringu (mastering engineer) otrzymuje gotowy miks i dopracowuje go tak, by brzmiał świetnie na każdej platformie — od Spotify po radio i płyty winylowe. Mastering to ostatni etap produkcji muzyki, który decyduje o jej ostatecznym brzmieniu.
Główne obowiązki:
Korekcja końcowego brzmienia (balans tonów i dynamiki);
Ujednolicenie głośności według standardów serwisów streamingowych;
Zachowanie spójności między utworami w albumie;
Konwersja do właściwych formatów (WAV, MP3, DDP itp.);
Sprawdzenie zgodności brzmienia na różnych urządzeniach.
Gdzie nauczyć się miksowania i masteringu?
Najlepsze szkoły muzyczne na świecie:
Berklee College of Music (USA) — lider w dziedzinie produkcji muzycznej;
SAE Institute — szkoły w całej Europie, także w Polsce (Warszawa, Kraków);
Abbey Road Institute — prestiżowa edukacja przy legendarnym studiu w Londynie;
Point Blank Music School — kursy z miksu i produkcji muzycznej;
Polskie uczelnie muzyczne: Uniwersytet Muzyczny Fryderyka Chopina, Akademia Muzyczna w Krakowie, AM w Katowicach.
Nauka online:
SoundGym, PureMix, Mix With The Masters, iZotope Learn, Coursera – idealne dla samouków i osób chcących doskonalić umiejętności w domu.
Gdzie można pracować?
Umiejętności miksowania i masteringu otwierają wiele drzwi:
Studia nagrań i firmy zajmujące się postprodukcją dźwięku;
Freelancing na platformach jak Fiverr, SoundBetter, Upwork;
Własne projekty muzyczne i produkcja dla innych artystów;
Asystentura u doświadczonych realizatorów w profesjonalnych studiach.
Ile zarabia inżynier miksu i masteringu?
Wynagrodzenie zależy od doświadczenia, lokalizacji i rodzaju pracy. USA / Kanada – 2500–4000 USD (Początkujący), 6000–10000 USD (Doświadczony), 100–1000 USD (Za utwór). Niemcy / Francja – 2000–3500 € (Początkujący), 5000–8000 € (Doświadczony), 80–600 € (Za utwór). Polska – 3000–7000 zł (Początkujący), 8000–15000 zł (Doświadczony), 200–1200 zł (Za utwór). Na freelansie stawki są bardzo zróżnicowane — zależą od jakości portfolio, opinii klientów i renomy w branży. W Polsce doświadczeni inżynierowie mogą zarabiać nawet do 1500 zł za utwór przy współpracy z wytwórniami lub artystami zagranicznymi.
Najlepsi inżynierowie współpracują z dużymi wytwórniami muzycznymi (Universal, Warner, Sony), tworzą utwory z list Billboardu i zdobywają nagrody Grammy za najlepsze brzmienie albumu. Wielu z nich zakłada własne studia nagraniowe lub dołącza do elitarnych społeczności, takich jak Mix With The Masters.
Znane nazwiska:
Chris Lord-Alge, Bob Ludwig, Tom Elmhirst, Emily Lazar — mistrzowie, którzy inspirują kolejne pokolenia realizatorów dźwięku także w Polsce.
Zamów mastering w AREFYEV Studio
Chcesz, żeby Twój utwór brzmiał jak profesjonalne wydania? Zgłoś się do AREFYEV Studio — specjalistów z wieloletnim doświadczeniem w miksie i masteringu. Nasze zalety:
Ponad 10 lat doświadczenia w pracy z muzyką;
Sprzęt analogowy i cyfrowy najwyższej klasy;
Dostosowanie brzmienia do platform streamingowych;
Indywidualne podejście do każdego projektu.
AREFYEV Studio – jakość, którą słychać! Skontaktuj się z nami już dziś i nadaj swojej muzyce brzmienie na światowym poziomie.