IK Multimedia ReSing Doubling: Can AI-Generated Vocal Doubles Replace Real Double Tracking?
Double tracking remains one of the most effective ways to increase vocal size, width, and perceived authority in a mix. Despite decades of advances in audio production technology, most major releases still rely on multiple vocal performances whenever a record demands scale without sacrificing intelligibility.
Recording convincing doubles still requires additional takes, editing, alignment, tuning, and level management before the vocal is ready to compete inside a finished production. As arrangements become more layered, the amount of work required to maintain believable vocal density increases accordingly.
But the technology raises a more important question than whether it can create wider vocals.
Can AI-generated doubles reproduce the musical and psychoacoustic benefits that make real double tracking so effective in the first place?
The answer extends well beyond a single plugin. It affects arrangement decisions, vocal production workflows, mixing strategy, stereo image management, and how modern productions translate across streaming platforms and consumer playback systems.
Contents
Why Vocal Doubling Has Become a Major Production Category
![]()
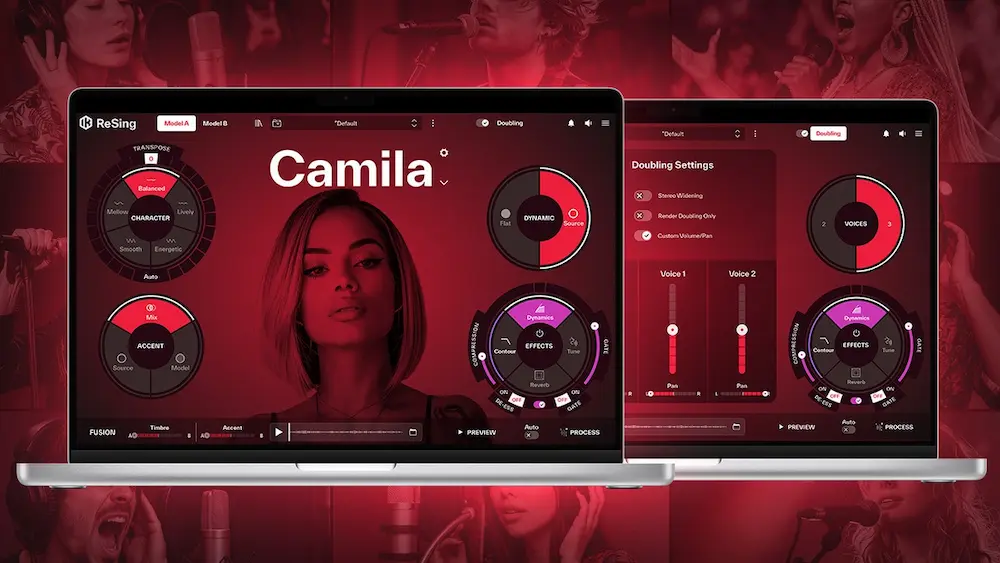
![]() Vocal doubling is no longer associated exclusively with major-label budgets or large commercial studios. It has become a standard production technique across modern music because listeners have grown accustomed to vocals that feel larger than a single performance can typically deliver.
Vocal doubling is no longer associated exclusively with major-label budgets or large commercial studios. It has become a standard production technique across modern music because listeners have grown accustomed to vocals that feel larger than a single performance can typically deliver.
Whether the genre is Pop, Hip-Hop, EDM, Alternative Rock, or Country, modern vocal production is increasingly built around controlled layering. The goal is not simply width. Producers are trying to increase vocal presence, maintain intelligibility in dense arrangements, and create a lead that remains competitive against increasingly complex productions.
That objective has not changed. The workflow has.
Independent artists now release music at a pace that would have been difficult to sustain a decade ago. Remote collaboration has become routine, production schedules have shortened, and many vocal sessions are recorded outside traditional studio environments. Under those conditions, recording, editing, and managing multiple vocal performances is often one of the most time-consuming stages of production.
As a result, an entire category of software has emerged around solving the same problem from different angles. Some tools focus on artificial double tracking. Others specialize in vocal alignment, harmony generation, performance cloning, or AI-assisted vocal creation. The common goal is reducing the amount of manual work required to build larger vocal arrangements.
That is the environment ReSing Doubling enters. Its significance is not that it can create additional vocal layers—numerous tools already do that. The more relevant question is whether modern AI-driven systems can generate vocal doubles that remain convincing once they leave solo playback and become part of a finished mix.

What IK Multimedia ReSing Doubling Is Actually Trying to Solve
The challenge facing every vocal doubling plugin is surprisingly simple: a copied vocal track is not a double.
Duplicating a waveform and placing it on another channel increases level, but it does little to create the spatial complexity associated with genuine double tracking. The sense of width listeners hear on professional recordings comes from performance variation, not duplication.
Every additional take introduces hundreds of small differences. Timing shifts, altered phrasing, changing consonant placement, breath timing, vibrato behavior, pitch drift, and dynamic inconsistencies prevent the vocal layers from behaving as a single source. Those imperfections are largely responsible for the depth and size associated with real double tracking.
Traditionally, there has been only one reliable way to achieve that result: record another performance.
ReSing Doubling attempts to approach the problem from a different direction. Rather than relying primarily on delay-based widening, modulation effects, or static pitch offsets, it aims to generate additional vocal performances derived from the original recording while introducing controlled variations between layers.
That distinction matters because conventional doubler plugins and performance-generation systems solve different problems.
Many classic doubling processors create the illusion of width through modulation, detuning, and stereo movement. They can be highly effective, particularly inside dense arrangements, but experienced engineers can often identify the effect because the vocal still behaves like a processed version of the original performance.
Tools such as ReSing Doubling are pursuing a more difficult objective. The goal is not simply to widen a vocal. The goal is to generate enough believable variation that the additional layer behaves less like an effect and more like an independently performed take.
Whether that goal can be achieved consistently across different vocal styles, genres, and production environments is ultimately the question that determines the value of the technology.
How ReSing Doubling Actually Works Inside ReSing
Much of the discussion around IK Multimedia ReSing Doubling focuses on the outcome rather than the mechanism. From a production perspective, however, understanding how the system builds additional voices is important because each mode introduces different mixing and arrangement implications.
The most conservative configuration is the 2 Voice mode. Rather than attempting to create a choir effect, the objective is to simulate the subtle performance variation associated with traditional double tracking. When used carefully, this mode is the most likely to support a lead vocal without drawing attention to itself.
The 3 Voice mode pushes the concept further by increasing perceived width and density. At this stage the tool begins moving beyond simple vocal reinforcement and into arrangement building. The generated layers contribute more energy to the mix, making balancing decisions increasingly important.
Ensemble mode represents the most ambitious implementation. Instead of simulating a second performer, the goal shifts toward creating the impression of multiple voices interacting simultaneously. This can be useful for background vocals, hooks, gang-style parts, and larger chorus sections where absolute realism is less critical than perceived scale.
The most significant controls are not necessarily the voice count parameters but the variation controls that determine how those voices behave. Timing variation affects how tightly the generated layers track the original performance. Small adjustments can create natural separation, while aggressive settings often move the result toward an obvious effect.
Pitch variation serves a similar purpose. Real vocal doubles rarely match pitch perfectly, and controlled detuning can help generated layers feel less mechanically related to the source. Excessive pitch variation, however, often creates the opposite effect by making the stack sound artificially constructed.
Stereo spread influences how the generated voices occupy the soundstage. Wider settings can create an immediate sense of scale, but they also increase the likelihood of translation issues on headphones, Bluetooth speakers, and mono-compatible playback systems.
Voice balancing may ultimately be the most important parameter of all. In professional vocal production, supporting layers are rarely intended to compete with the lead. The most successful ReSing Doubling workflows will likely involve generated voices that remain subordinate to the primary performance rather than attempting to dominate it.
Viewed from an engineering perspective, the effectiveness of ReSing Doubling is determined less by how many voices it can create and more by how precisely those voices can be controlled once they become part of a complete mix.
The Real Production Question: Performance Simulation vs Performance Capture
Much of the discussion surrounding AI-assisted vocal production assumes that generating a convincing double is primarily a technical problem. In reality, the challenge is musical.
Professional double tracking is not valuable because the second take arrives a few milliseconds earlier or later than the original. Its value comes from the fact that a human being performs the part twice.
No vocalist repeats a phrase identically. Vowels shift slightly. Consonants land in different places. Breath support changes from line to line. Vibrato develops differently. Certain words receive more emphasis while others become less pronounced. None of these variations are dramatic on their own, yet together they create the depth, movement, and unpredictability associated with authentic vocal layering.
This is where performance simulation becomes considerably more difficult than traditional vocal processing.
Creating variation is relatively easy. Creating variation that feels musically intentional is not.
Most doubling effects can produce a wider stereo image. Far fewer can generate the impression that another performance actually took place. Experienced engineers tend to recognize the difference quickly because human performances contain inconsistencies that rarely follow predictable patterns.
The distinction becomes even more important as vocal arrangements grow larger. A subtle generated double tucked beneath a lead vocal may blend naturally into the production. Once multiple AI-generated layers begin interacting inside a chorus stack, listeners are exposed to far more opportunities to hear what is real, what is repeated, and what has been artificially constructed.
That is often where the gap between performance capture and performance simulation becomes most apparent. The technology may successfully create additional voices, but creating the illusion of multiple performers remains a far more demanding task.
Where ReSing Doubling Makes Practical Sense
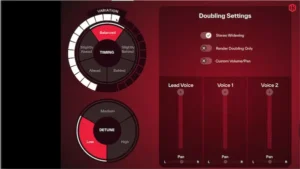 The most effective applications for ReSing Doubling are not necessarily the ones that attempt to replace traditional vocal production. Its value increases when the goal is efficiency rather than absolute realism.
The most effective applications for ReSing Doubling are not necessarily the ones that attempt to replace traditional vocal production. Its value increases when the goal is efficiency rather than absolute realism.
One obvious use case is lead vocal reinforcement. A carefully blended generated double can increase perceived size and stability without resorting to heavy modulation effects, aggressive widening processors, or obvious chorus treatments. In dense Pop, EDM, and modern Hip-Hop productions, that additional support may help a vocal remain present without requiring significant level increases.
IK Multimedia ReSing Doubling also makes practical sense during the songwriting and demo stage. Producers frequently need to evaluate how a vocal arrangement will behave before investing time in final recordings. Building temporary doubles and stacks from a single performance can accelerate creative decisions and reveal whether additional layers are actually necessary.
Fast-turnaround production environments present another logical application. Content creators, independent artists, and remote collaborators often work under deadlines that leave little room for additional vocal sessions. In those situations, generating usable supporting layers may be more valuable than pursuing perfect authenticity.
Background vocals may ultimately represent the strongest fit for this type of technology. Supporting layers generally receive less scrutiny than exposed lead performances, and small artifacts that become noticeable in isolation often disappear once the vocals are integrated into a complete arrangement. When used to build depth behind a lead rather than replace it, generated doubles have a much greater chance of sounding convincing.
That distinction is important. The technology becomes most useful when treated as an arrangement tool rather than a substitute for a skilled vocalist recording another take.
A Real-World Vocal Production Workflow Using ReSing Doubling
The most realistic way to evaluate IK Multimedia ReSing Doubling is not through isolated demonstrations but through a complete production workflow.
A typical session may begin with a single lead vocal that lacks the density required to compete against a modern arrangement. Instead of immediately recording additional takes, a producer can generate a secondary vocal using ReSing Doubling and evaluate whether the arrangement actually benefits from increased layering.
If the additional voice improves the presentation, further layers can be introduced to create a wider stack for choruses, hooks, or supporting vocal sections. At this stage the objective is not maximum width but controlled density that remains subordinate to the lead.
Once the vocal structure is established, the project enters the mixing phase. Generated doubles must be balanced against the lead vocal, integrated into the stereo image, and managed carefully to avoid excessive midrange congestion.
The next stage is mastering, where vocal density begins interacting with compression, limiting, and overall loudness optimization. A stack that feels exciting during production may require adjustment once the mix is pushed toward release levels.
The final evaluation happens during translation testing. Earbuds, smartphones, Bluetooth speakers, vehicle audio systems, and streaming platforms often reveal issues that remain hidden on studio monitors.
This workflow highlights an important reality. The success of ReSing Doubling is not determined when the additional voice is generated. It is determined when that voice continues to support the record after mixing, mastering, and real-world playback are taken into account.
Where Engineers May Still Prefer Real Double Tracking
The limitations of IK Multimedia ReSing Doubling and similar AI-generated doubling systems become more apparent as production standards rise.
In highly exposed vocal productions, engineers are not simply looking for width or density. They are looking for the subtle interactions that occur when multiple performances of the same part coexist within a mix. Those interactions often contribute as much to the emotional impact of a record as the vocal itself.
That is particularly true in contemporary Pop, Country, cinematic productions, and singer-songwriter material where the vocal serves as the primary focal point. In these contexts, listeners are not reacting only to lyrics or melody. They are responding to tiny fluctuations in phrasing, dynamics, articulation, and emotional delivery that naturally occur from take to take.
Those characteristics are difficult to synthesize because they are rarely predictable. A vocalist may lean into a word differently, alter the shape of a phrase, push a consonant harder, or introduce a slight dynamic change that was never consciously planned. These moments often create the sense of realism that separates a layered vocal from a processed vocal.
This is where many artificial doubling systems face their greatest challenge. They may generate convincing variation, yet still struggle to reproduce the organic unpredictability of a genuine performance. The result can sound polished and technically sophisticated while remaining somewhat static from an emotional perspective.
In dense electronic productions, that distinction may be largely irrelevant. Once vocals are competing with layered synths, programmed drums, effects returns, and aggressive processing, the advantages of a real double can become less noticeable. In sparse arrangements, however, there is far less information competing for the listener’s attention.
The fewer elements surrounding the vocal, the more exposed every production decision becomes. Under those conditions, a well-recorded second take remains difficult to replace.
Why This Matters During Mixing
Producers often evaluate vocal doubles based on what they add. Mixing engineers tend to evaluate them based on what they complicate. This distinction highlights the broader difference between mixing and mastering, where production decisions are assessed not only for creative impact but also for translation and playback consistency.
A vocal layer does not exist in isolation. Every additional performance occupies space within an arrangement and competes for bandwidth inside the mix. What initially sounds larger during production can create new challenges once the vocal must coexist with drums, bass, instruments, effects returns, and bus processing.
One of the most common mistakes with generated vocal doubles is assuming that creating additional vocal layers automatically improves a mix. In practice, every generated voice increases competition in the most important frequency range of a record. What sounds impressive during production can quickly become a masking problem during mixing, particularly once compression, saturation, reverbs and stereo processing are introduced.
Artificial doubles influence far more than stereo width. They affect center image stability, vocal intelligibility, phase relationships, reverb perception, transient definition, and the amount of midrange information competing for attention. As layers accumulate, maintaining vocal focus often becomes more difficult rather than less.
This is particularly relevant because the human voice already occupies one of the most crowded regions of a modern mix. Introducing additional vocal information into the same frequency range can increase perceived size while simultaneously reducing clarity. The result may sound impressive during solo playback yet become harder to position once the entire production is playing.
Experienced engineers frequently encounter sessions where vocal stacks are reduced rather than expanded. Not because the layers sound bad individually, but because removing a few of them restores focus to the lead performance and improves overall translation.
The issue becomes even more apparent outside the studio. Earbuds, smartphones, Bluetooth speakers, vehicle audio systems, and other consumer playback environments tend to expose vocal congestion more aggressively than professional monitoring systems. A vocal arrangement that feels massive in the control room can quickly lose definition in real-world listening conditions.
For that reason, the success of a vocal doubling tool is not determined solely by how much width it creates. The more important question is whether the additional layers continue serving the song once the mix leaves the studio and enters the environments where most listeners actually hear music.
Critical Evaluation: Where the Marketing Narrative Meets Production Reality
 IK Multimedia ReSing Doubling illustrates a broader reality: most vocal doubling technologies sound better in demonstrations than they do in finished productions.
IK Multimedia ReSing Doubling illustrates a broader reality: most vocal doubling technologies sound better in demonstrations than they do in finished productions.
That is not necessarily a flaw in the software. It is a consequence of how vocal layers are typically evaluated. A generated double auditioned in isolation can appear remarkably convincing because the listener is focused on the vocal itself. Once that same vocal enters a complete mix, the criteria change.
The relevant question is no longer whether the additional layer sounds realistic. The question is whether it improves the record.
A convincing vocal double still has to survive arrangement density, bus compression, stereo summing, spatial effects, mastering processing, and the compromises introduced by consumer playback systems. Many of the issues discussed in this article eventually appear as common mastering problems when excessive vocal layering reduces clarity and translation. Many vocal enhancement tools perform well at the source level yet contribute less value once the entire production is assembled.
Stereo width is often where expectations become disconnected from reality. Additional width creates an immediate impression of scale, which makes it one of the easiest effects to market and one of the easiest effects to overuse. The problem is that vocal size and vocal focus are not always moving in the same direction.
Every engineer eventually encounters a mix where widening the vocal makes it feel larger but simultaneously makes it less effective. The center image remains the anchor of most commercial productions, particularly in genres where vocal intelligibility drives listener engagement. If added width begins to weaken that anchor, the apparent improvement may come at the expense of translation.
This is where restraint becomes more important than processing power. Features such as timing variation, pitch offset, stereo placement, and level control provide flexibility, but flexibility alone does not guarantee a stronger production. Successful vocal doubling often depends on deciding how little enhancement is necessary rather than how much can be applied.
That reality is easy to overlook because modern production tools make vocal multiplication almost effortless. Adding layers is rarely difficult. Creating separation between those layers, preserving vocal focus, and maintaining clarity throughout a mix is where the real work begins.
Many commercially successful records rely on surprisingly disciplined vocal arrangements. Their sense of scale comes from contrast, automation, arrangement choices, and selective layering rather than constant vocal expansion. More voices can create a bigger sound, but they can also create additional masking, increased midrange congestion, and reduced definition around the lead.
Viewed through that lens, the value of ReSing Doubling is not measured by how many voices it can generate. The more relevant measure is how effectively those additional voices support the lead vocal without competing against it.
How ReSing Doubling Fits Into the Current Vocal Production Landscape
The challenge in evaluating ReSing Doubling is that it does not compete directly against a single category of software.
The modern vocal production market is fragmented. Some tools focus on creating width. Others generate harmonies, align performances, clone voices, correct pitch, or manipulate timing. Although these products are often grouped together under the broad umbrella of vocal production, they are solving fundamentally different problems.
IK Multimedia ReSing Doubling occupies a narrower position. It is not designed to replace a vocalist, generate harmonies, or align existing takes. Its primary purpose is to create additional vocal performances from a single source and reduce the amount of manual work traditionally required to build vocal layers.
That positioning makes comparisons more meaningful because the most relevant alternatives are not necessarily other AI tools. In many cases, the real competition remains traditional double tracking.
Viewed through the lens of professional vocal production rather than marketing claims, ReSing Doubling performs best as a workflow acceleration tool. The following ratings reflect its practical value inside modern recording, mixing, and mastering workflows.
| Approach | Primary Goal | Advantages | Limitations | Best Application |
|---|---|---|---|---|
| ReSing Doubling | Generate additional vocal layers from one performance | Fast workflow, instant doubles and stacks | May not fully replicate natural performance variation | Modern production, demos, supporting vocal layers |
| Real Double Tracking | Create genuine performance variation | Maximum realism, natural interaction between takes | Requires additional recording and editing | Commercial releases, exposed lead vocals |
| Traditional Doubler Plugins | Create perceived width through processing | Fast, lightweight, proven workflows | Often sounds processed rather than performed | Rock, Pop, EDM vocal enhancement |
| VocAlign-Style Alignment Tools | Tighten existing vocal performances | Industry-standard editing precision | Cannot create new performances | Professional multi-track vocal production |
| AI Voice Generation Systems | Create or clone vocal performances | Maximum flexibility | Authenticity and workflow concerns | Experimental production workflows |
The table highlights an important distinction. ReSing Doubling is not attempting to outperform every vocal production tool on the market. It is addressing a specific gap between traditional doubling effects and recording additional performances.
Whether that approach is successful depends largely on expectations. Producers expecting a perfect substitute for a professionally recorded double may find the technology less convincing. Producers looking to build vocal density quickly without scheduling another recording session are likely to view the value proposition very differently.
Viewed in practical terms, ReSing Doubling is best understood as a workflow tool rather than a replacement for professional vocal production. The closer it is positioned to that role, the easier it becomes to evaluate its strengths and limitations realistically.
Who Should Actually Consider Using ReSing Doubling?
IK Multimedia ReSing Doubling is most relevant for producers working in environments where recording additional performances is difficult, expensive, or simply impractical.
That typically includes independent producers building arrangements from limited vocal material, electronic music producers working primarily with delivered stems, songwriters developing production concepts before final tracking sessions, and remote collaborators who do not always have immediate access to the original vocalist.
In these workflows, the objective is rarely to replace professional vocal production. The objective is to create enough vocal density to support arrangement decisions, strengthen a lead vocal, or build supporting layers without interrupting the production process.
The value proposition becomes less compelling once a project already contains properly recorded doubles, harmonies, and background vocals. At that point, the production has access to something software still struggles to replicate consistently: genuine performance interaction between multiple takes.
For mixing engineers, the usefulness of the tool often depends on the material arriving at the session. If the vocal production is already complete, there may be little reason to generate additional layers. If the project arrives with a single exposed vocal and no supporting performances, the equation changes considerably.
That is ultimately where tools like ReSing Doubling earn their place. They are not competing against great vocal recordings. They are competing against the absence of additional recordings altogether.
Viewed from that perspective, the question is not whether an AI-generated double can outperform a professionally recorded one. The more practical question is whether it can improve a production when a second performance simply does not exist.
Who Probably Doesn’t Need It?
Not every vocal production problem requires a technological solution.
Some genres depend on intimacy, vulnerability, and performance detail far more than they depend on vocal scale. In those productions, the goal is often to preserve the nuances of a single performance rather than expand it with additional layers.
Engineers working on acoustic singer-songwriter material, jazz recordings, certain classical crossover projects, and other performance-driven productions may find limited value in AI-generated doubles because the underlying aesthetic priorities are different. The listener’s attention is focused on the performance itself, not the perceived size of the vocal image.
Under those conditions, additional vocal layers can sometimes move a production further away from its artistic objective. A vocal that feels intimate and direct may become less engaging once artificial width and density are introduced.
There is also a practical consideration. Engineers working in performance-driven genres often spend significant effort removing anything that sounds overly processed. In those environments, generated vocal layers can introduce additional complexity without solving an existing production problem.
The same principle applies to vocalists who consistently deliver strong doubles. If a singer can provide multiple high-quality performances without significant additional studio time, recording another take remains one of the most effective solutions available. The resulting interaction between performances often contributes more to the final record than any processing chain applied afterward.
This is an important distinction because software and performance are not always competing solutions. In many professional workflows, the best vocal double is still the one created in front of a microphone rather than generated afterward.
Which Genres Benefit Most From AI Vocal Doubling?
Not every genre places the same demands on vocal production, which means the value of IK Multimedia ReSing Doubling varies significantly depending on the musical context.
Modern Pop is perhaps the most natural fit. Contemporary Pop arrangements often rely on multiple vocal layers, reinforced choruses, and carefully controlled vocal width. Generated doubles can help producers build that density quickly without interrupting the writing process.
EDM is another strong candidate because vocals frequently compete against highly compressed drums, layered synthesizers, and dense arrangements. Subtle vocal reinforcement can improve presence without dramatically changing the character of the lead.
Hyperpop may benefit even more because the genre often embraces artificiality as part of its aesthetic identity. In these productions, generated layers can become a creative choice rather than merely a production shortcut.
Modern Country occupies an interesting middle ground. Choruses often benefit from additional vocal support, but listeners still expect a strong sense of authenticity from the lead performance. Moderation becomes particularly important.
Hip-Hop producers may find the greatest value in vocal reinforcement and hook construction rather than traditional double tracking. Supporting layers can help key phrases and choruses maintain authority without requiring extensive recording sessions.
Singer-songwriter productions generally present the greatest challenge. These arrangements often depend on intimacy and performance nuance, making artificial vocal expansion less beneficial than it is in denser commercial genres.
Ultimately, the more a genre prioritizes scale, density, and vocal layering, the more likely it is to benefit from AI-assisted doubling workflows.
Real-World Production Perspective: Mixing, Mastering, and Translation
The true test of any vocal doubling strategy begins after the production stage is finished.
Inside a DAW session, additional vocal layers almost always create an immediate impression of size. The more difficult question is whether that perceived improvement survives the entire delivery chain, from mix bus processing and mastering to streaming codecs and consumer playback systems.
Every vocal layer contributes energy to the most competitive region of a modern mix. As additional doubles are introduced, engineers must manage not only width and depth, but also midrange congestion, center image stability, phase interaction, and the relationship between the vocal and the rest of the arrangement.
These issues often become more apparent during mastering. A vocal stack that feels exciting during production can behave differently once broadband compression, limiting, and final level optimization are applied. This becomes particularly relevant in modern loudness workflows where stereo content, transient density, and center-image stability directly influence limiter behavior, a topic explored in our Pulsar Modular P21 Atlas review.
This is one reason experienced mastering engineers tend to evaluate vocal production holistically rather than focusing on individual layers. As explained in How Professional Mastering Works, mastering decisions are made in the context of the entire mix rather than isolated elements. The question is not whether a generated double sounds convincing on its own. The question is whether the entire vocal structure continues to serve the record once the mix is pushed toward commercial release levels.
Translation ultimately becomes the deciding factor. Consumer listening environments are far less forgiving than studio monitors. Earbuds, smartphones, vehicle audio systems, Bluetooth speakers, laptops, and streaming platforms often reveal congestion that remains hidden in a controlled studio environment.
A well-executed doubling strategy should maintain vocal intelligibility, preserve center focus, and remain stable across different playback systems. If the vocal begins to lose definition, drift away from the center image, or compete excessively with surrounding instruments, the arrangement may contain more layers than the production actually needs. Issues like these are often easier to solve during mix preparation than during mastering, which is why proper mix preparation for mastering remains critical.
This principle applies equally to AI-generated doubles and traditionally recorded performances. The difference is largely one of workflow. Artificial doubling makes it easy to build increasingly complex vocal stacks, which can encourage producers to add layers that would never have been recorded manually.
That convenience is both the strength and the risk of modern vocal production technology. Generating additional voices has become remarkably easy. Determining whether those voices improve the final record remains an engineering decision.
The Bigger Industry Implication
IK Multimedia ReSing Doubling is interesting for reasons that extend beyond vocal production.
For most of the modern recording era, audio software has been designed to process, enhance, repair, or manipulate material that already exists. Engineers recorded performances first and used technology afterward to shape the result.
That relationship is beginning to change.
An increasing number of production tools are no longer focused solely on processing recorded audio. They are being developed to generate material that was never captured in the first place. Vocal doubles, harmonies, instrumental parts, and even complete performances can now be created algorithmically rather than recorded traditionally.
This trend extends beyond vocals. Recent tools increasingly blur the line between sound design, performance generation, and production assistance. A good example is The Crow Hill Company Crystal Pads, where generated textures and adaptive sound design workflows shift part of the creative process from performance toward intelligent content creation.
This shift represents a meaningful change in how software participates in the production process. The conversation is no longer limited to better EQs, cleaner compressors, or more transparent mastering tools. It increasingly revolves around whether software should assist with performance creation itself.
ReSing Doubling sits within that transition. The product is not simply offering another method of vocal enhancement; it is part of a broader movement toward performance generation as a production workflow.
Whether that approach ultimately becomes standard practice is less important than the direction of travel. Producers have already demonstrated a willingness to incorporate AI-assisted editing, stem separation, automatic transcription, intelligent mixing tools, and generative production systems into everyday workflows.
Against that backdrop, generating additional vocal performances from a single take feels less like an isolated innovation and more like a logical extension of where music production is already heading.
The most important question is no longer whether software can generate additional performances. That threshold has already been crossed. The more meaningful question is where producers choose to draw the line between captured performance and generated performance as these tools become increasingly common inside commercial production workflows.
Is ReSing Doubling Worth It?
For producers working with limited vocal material, ReSing Doubling can eliminate hours of additional recording, editing, and vocal preparation. Its value becomes less obvious in workflows that already include professionally recorded doubles, harmonies, and supporting vocal arrangements. The plugin is easiest to justify as a workflow accelerator rather than a replacement for traditional vocal production.
Overall Rating
| Category | Rating |
|---|---|
| Workflow Acceleration | 9.5/10 |
| Vocal Layer Realism | 8/10 |
| Lead Vocal Support | 8.5/10 |
| Background Vocal Production | 9/10 |
| Mix Integration | 8/10 |
| Translation Potential | 8/10 |
| Value for Money | 9/10 |
| Overall | 8.6/10 |
ReSing Doubling succeeds when it is treated as a workflow tool rather than a replacement for professional vocal recording. Its greatest strength is the ability to generate useful vocal density from limited source material, allowing producers to build doubles and supporting layers in seconds rather than scheduling additional recording sessions. While it cannot consistently reproduce the nuance and unpredictability of genuine multi-performance tracking, it offers a practical solution for modern production environments where speed, flexibility, and vocal arrangement efficiency often matter as much as absolute realism.
Verdict
ReSing Doubling is at its most convincing when it is viewed as a production tool rather than a performance replacement system.
The software addresses a legitimate workflow problem. Many producers routinely work with sessions that contain only a single vocal performance, yet the arrangement calls for greater density, width, or support. In those situations, the ability to generate usable doubles and supporting layers from existing material can save considerable time and help move a production forward.
Its strengths become less clear when the objective shifts from augmentation to replication. The technology can generate additional voices, but generating additional voices is not the same thing as reproducing the interaction between multiple human performances. That distinction remains important, particularly in productions where the vocal carries significant emotional weight.
For engineers pursuing maximum realism, traditional double tracking remains the reference point. The combination of natural timing variation, phrasing differences, articulation changes, and performance nuance continues to provide advantages that are difficult to reproduce algorithmically.
That does not diminish the usefulness of the tool. It simply defines its role more accurately.
Used with realistic expectations, ReSing Doubling can be an effective addition to modern vocal production workflows. It is most valuable for building supporting layers, reinforcing lead vocals, accelerating arrangement development, and solving practical production constraints when additional recordings are unavailable.
Ultimately, the success of technology like this will not be determined by how many vocal layers it can generate. It will be determined by how well those layers integrate into finished productions, survive mixing and mastering, and continue to sound convincing once they reach real listeners through real playback systems.

Yurii Ariefiev is a mastering engineer and audio production editor specializing in mix translation, streaming optimization, and modern release workflows. His work focuses on how production decisions made during recording, vocal processing, mixing, and mastering affect real-world playback across consumer listening systems.
This article examines AI-generated vocal doubling from a production and mastering perspective, focusing on vocal translation, stereo image stability, arrangement density, and the practical differences between generated vocal layers and traditionally recorded double-tracked performances.

FAQ
Can IK Multimedia ReSing Doubling replace real vocal doubles?
It can reduce the need for additional recording in certain workflows, particularly demos, electronic productions, and content-driven projects. However, when a production depends heavily on vocal realism and performance nuance, a genuine second take remains difficult to replicate.
How does ReSing Doubling differ from a traditional vocal doubler plugin?
Traditional doubler plugins typically create width through delay, modulation, and pitch variation. ReSing Doubling is designed to generate additional vocal performances from a single source, making it closer to performance simulation than conventional vocal processing.
Does vocal doubling make a mix sound more professional?
Not necessarily. Effective vocal production depends on arrangement, balance, and context. Additional layers can increase perceived size, but they can also introduce masking and reduce vocal focus if used excessively.
Can AI-generated vocal doubles create phase issues?
Potentially. Any layered vocal arrangement can introduce phase interaction, particularly when multiple voices share similar timing and frequency content. Checking mono compatibility remains an important part of the mixing process.
Is ReSing Doubling useful for mixing engineers?
Its value depends on the source material. Engineers working with incomplete vocal productions may find it useful for generating supporting layers, while sessions that already include doubles, harmonies, and backing vocals are less likely to benefit.
How do generated vocal doubles behave during mastering?
Additional vocal layers can influence center image stability, perceived density, and midrange balance. These effects often become more noticeable after compression and limiting are applied during mastering.
Will vocal stacks translate well to streaming platforms?
Well-balanced vocal stacks generally translate without issue. Problems tend to appear when excessive width, layering, or phase interaction reduces intelligibility after streaming codecs and consumer playback systems are introduced.
Can ReSing Doubling replace tools like VocAlign?
No. The two products address different stages of vocal production. VocAlign aligns existing performances, while ReSing Doubling generates additional ones. Many workflows could potentially use both.
Does adding more vocal layers always create a bigger chorus?
Not always. Chorus size is influenced by contrast, arrangement, automation, and frequency balance as much as by the number of vocal tracks. Additional layers can increase impact, but they can also dilute the lead vocal if not managed carefully.
Who is likely to get the most value from ReSing Doubling?
Producers working with limited vocal material, remote collaborations, stem-based productions, and fast-turnaround projects are likely to benefit most. The software is particularly useful when additional recordings are unavailable rather than when they already exist.
Does ReSing Doubling add noticeable CPU load to large sessions?
CPU requirements will vary depending on session complexity and the number of generated voices being used simultaneously. In most workflows, the larger consideration is not processing power but session management, as additional vocal layers can increase routing, automation, and balancing requirements throughout the mix.